
So in today’s blog, we will be building a Credit Card Fraud Detection model which will be very simple and easy to understand. This is a very basic machine learning project which students basically do in their starting phase of learning machine learning. So without any further due, Let’s do it…
Step 1 – Importing required libraries for Credit Card Fraud Detection.
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.preprocessing import RobustScaler from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report,confusion_matrix,accuracy_score %matplotlib inline
Step 2 – Reading our input data for Credit Card Fraud Detection.
df=pd.read_csv('creditcard.csv')
df.head()

Step 3 – Describing our data for Credit Card Fraud Detection.
df.describe()
- Here we can see that all the columns are normalized except the Time and Amount columns.
- So we will normalize them further.

Step 4 – Plotting Amount vs Class.
sns.jointplot(new_df['scaled_amount'],new_df['Class'])
- From the plot below we can infer that most of the fraud transactions were done for a relatively lesser amount.
- All the 1s are on the left-hand side of the plot, which means a lesser amount.

Step 5 – Scaling our unscaled columns.
rbs = RobustScaler() df_small = df[['Time','Amount']] df_small = pd.DataFrame(rbs.fit_transform(df_small)) df_small.columns = ['scaled_time','scaled_amount'] df = pd.concat([df,df_small],axis=1) df.drop(['Time','Amount'],axis=1,inplace=True) df.head()
- Line 1 – Instantiating Robust Scaler object.
- Line 3 – Creating a new dataframe with just the Time and Amount columns of our original dataframe.
- Line 4 – Transforming data using RobustScaler. We could have also used StandardScaler but RobustScaler is lesser prone to outliers as compared to StandardScaler and can handle them efficiently.
- Line 6 – Rename the columns in new dataframe.
- Line 7 – Join both dataframes.
- Line 9 – Drop the old unscaled Time and Amount columns.

Step 6 – Visualizing our unbalanced dataset.
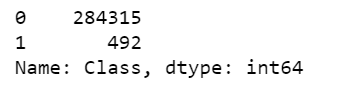
- From the values and plot below we can infer that our dataset is highly unbalanced because we are having 284315 non-fraudulent transactions and 492 fraudulent transactions.
- Our model when trained on this data will give 99% accuracy because it will simply predict non-fraudulent every time and hence it will be proven as a very bad model.
- That’s why to tackle this we need to balance our dataset.
df['Class'].value_counts()
sns.countplot(df['Class'])

Step 7 – Balancing dataset for Credit Card Fraud Detection.
non_fraud = df[df['Class']==0] fraud = df[df['Class']==1] non_fraud = non_fraud.sample(frac=1) non_fraud = non_fraud[:492] new_df = pd.concat([non_fraud,fraud]) new_df = new_df.sample(frac=1)
- Line 1 – Taking out all the non_fraud transactions from our dataset.
- Line 2 – Taking out all the fraud transactions from our dataset.
- Line 4 – df.sample is used to randomly take out some fraction of data from the data frame. Here we are using frac=1 means take out 100% of data. This step simply helps in shuffling the data.
- Line 6 – After shuffling just take the first 492 instances/transactions of non_fraud because we have only 492 transactions of fraud. That’s why to exactly balance the data we are doing this step.
- Line 8-9 – Join both datasets and name it new_df and shuffle it again.
Step 8 – Visualizing our balanced dataset.
- We can see below that our dataset is balanced.
- Both classes have 492 instances each.
new_df['Class'].value_counts()

sns.countplot(new_df['Class'])

Step 9 – train-test-split our data for Credit Card Fraud Detection.
X = new_df.drop('Class',axis=1)
y = new_df['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=101)
- Splitting our data into 80%-20% proportions for training and testing purposes respectively.
Step 10 – Training our LogisticRegresion model for Credit Card Fraud Detection.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train,y_train)
pred = lr.predict(X_test)
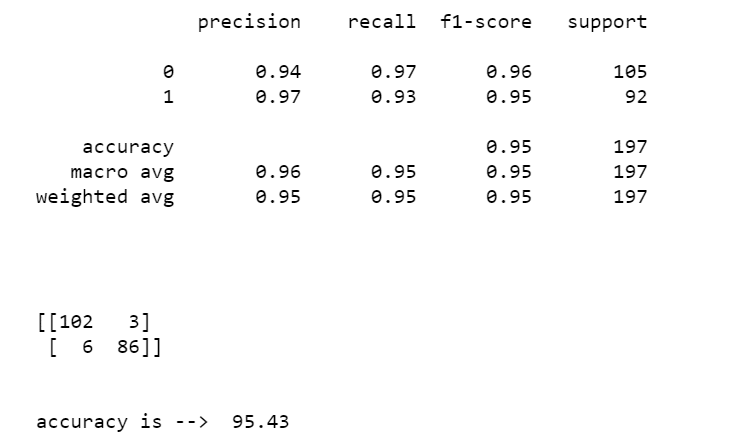
print(classification_report(y_test,pred))
print('\n\n')
print(confusion_matrix(y_test,pred))
print('\n')
print('accuracy is --> ',round(accuracy_score(y_test,pred)*100,2))
- In this step, we are simply using LogisticRegression for this use case.
- I also tried Random Forest and Decision Tree Classifiers but Logistic Regression stood out.
- Then we are simply calculating some metrics like classification reports, confusion matrices, and accuracy scores and print them.
Download Data…
Download the Source Code…
Do let me know if there’s any query regarding this topic by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
Read my previous post: SPAM DETECTION USING COUNT VECTORIZER
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.