
So guys in today’s blog we will see how to extract tables from PDF files and save them as CSV files using just 3-4 lines of code.
This use-case can be very useful when you need to extract n number of tables from a PDF File. So without any further due, let’s do it…
Check out this Table Extractor Flask App also…
Snapshot of our Final CSV…

Step 1 – Install Camelot
- To install the Camelot library, run the following command in your terminal.
pip install "camelot-py[cv]"
Step 2 – Importing required libraries
- For today’s use case, we just need to import the Camelot library.
import camelot
Step 3 – Reading the PDF file.
- Download the pdf file.
- Here we are simply using camelot.read_pdf function to read our PDF file and extract tables from it automatically.
- If our PDF has more than 1 page, we can also specify the page numbers from which we need to read the CSVs.
- Also if our PDF file is password protected we can pass the password of the file as the parameter to the read_pdf function.
tables = camelot.read_pdf('table.pdf')
# tables = camelot.read_pdf('table.pdf', pages='1,2,3,5-7,8')
# tables = camelot.read_pdf('table.pdf', password='*******')
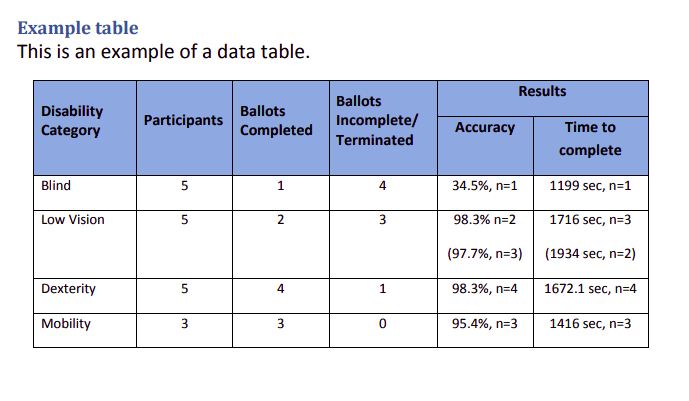
Step 4 – Let’s extract tables from PDF files
- As we already know that our PDF File is having just one table so we will just do tables[0].df, means print the 0th element(table) in our tables as a dataframe.
- When you are working with multiple tables simply run a for-loop.
#Access the ith table as Pandas Data frame tables[0].df
Step 5 – Save the table in CSV format
- Simply use the tables.export method to save the tables in CSV format.
tables.export('found_table.csv', f='csv')
Step 6 – Visualizing the conversion metrics
- Use the tables[0].parsing_report to visualize the conversion metrics.
tables[0].parsing_report
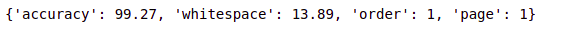
- Read more about the advanced usage of camelot library here.
And in this way you can Extract Tables from PDF files…
Challenges in extracting tables from PDF files
Extracting tables from PDF files can be challenging due to the varying layouts, formatting inconsistencies, and lack of structured data. Manual extraction processes can be time-consuming and error-prone.
Tools and methods for extracting tables from PDF files
There are several tools and methods available for extracting tables from PDF files:
- Manual extraction: Copying and pasting data from PDF to CSV manually.
- Using Python libraries: Utilizing Python libraries such as
tabula-pyandcamelotfor automated extraction. - Online converters: Using online tools like Smallpdf or PDFTables for quick conversion.
Use cases of extracted tables in CSV format
Extracted tables in CSV format can be utilized for:
- Data analysis and visualization
- Database management and integration
- Report generation and documentation
Conclusion
Extracting tables from PDF files and saving them as CSV format is a valuable skill in data management and analysis. By leveraging Python libraries and other tools, users can efficiently extract and utilize tabular data from PDF documents.
So this is all for this blog folks. Thanks for reading it and I hope you are taking something with you after reading this and till the next time…
FAQs
Can I extract tables from scanned PDF files?
Yes, you can use OCR (Optical Character Recognition) tools in combination with table extraction libraries to extract tables from scanned PDFs.
Are there any limitations to using Python libraries for table extraction?
While Python libraries offer powerful capabilities, they may struggle with highly complex PDF layouts or poorly structured tables.
Is it legal to extract tables from PDF files for personal or commercial use?
It depends on the terms of use of the PDF files and the purpose of extraction. Always ensure compliance with copyright laws and permissions.
Can I extract tables from password-protected PDF files?
In most cases, you cannot extract tables from password-protected PDF files without the password. Ensure you have the necessary permissions to access the PDF content.
How can I handle tables that span multiple pages in a PDF file?
Python libraries like camelot offer features to handle multi-page tables. You can specify options to extract tables spanning multiple pages.
Read my previous post: How to Deploy a Flask app online using Pythonanywhere
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, and Flask projects at machinelearningprojects.net.