
Today’s blog is going to be a very interesting blog where we will be performing Flipkart Reviews extraction and sentiment analysis and also we will be creating a beautiful-looking GUI using HTML and CSS.
So without any further due, Let’s do it…
Create a conda environment and install the required libraries
conda create -n flipkart python=3.9 conda activate flipkart pip install flask nltk requests numpy bs4 matplotlib wordcloud
Code for Flipkart Reviews extraction and sentiment analysis…
app.py
import re
import os
import nltk
import joblib
import requests
import numpy as np
from bs4 import BeautifulSoup
import urllib.request as urllib
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
from wordcloud import WordCloud,STOPWORDS
from flask import Flask,render_template,request
import time
# Flipkart Reviews extraction and sentiment analysis
# nltk.download('stopwords')
# nltk.download('punkt')
# nltk.download('wordnet')
app = Flask(__name__)
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = 0
def clean(x):
x = re.sub(r'[^a-zA-Z ]', ' ', x) # replace evrything thats not an alphabet with a space
x = re.sub(r'\s+', ' ', x) #replace multiple spaces with one space
x = re.sub(r'READ MORE', '', x) # remove READ MORE
x = x.lower()
x = x.split()
y = []
for i in x:
if len(i) >= 3:
if i == 'osm':
y.append('awesome')
elif i == 'nyc':
y.append('nice')
elif i == 'thanku':
y.append('thanks')
elif i == 'superb':
y.append('super')
else:
y.append(i)
return ' '.join(y)
def extract_all_reviews(url, clean_reviews, org_reviews,customernames,commentheads,ratings):
with urllib.urlopen(url) as u:
page = u.read()
page_html = BeautifulSoup(page, "html.parser")
reviews = page_html.find_all('div', {'class': 't-ZTKy'})
commentheads_ = page_html.find_all('p',{'class':'_2-N8zT'})
customernames_ = page_html.find_all('p',{'class':'_2sc7ZR _2V5EHH'})
ratings_ = page_html.find_all('div',{'class':['_3LWZlK _1BLPMq','_3LWZlK _32lA32 _1BLPMq','_3LWZlK _1rdVr6 _1BLPMq']})
for review in reviews:
x = review.get_text()
org_reviews.append(re.sub(r'READ MORE', '', x))
clean_reviews.append(clean(x))
for cn in customernames_:
customernames.append('~'+cn.get_text())
for ch in commentheads_:
commentheads.append(ch.get_text())
ra = []
for r in ratings_:
try:
if int(r.get_text()) in [1,2,3,4,5]:
ra.append(int(r.get_text()))
else:
ra.append(0)
except:
ra.append(r.get_text())
ratings += ra
print(ratings)
@app.route('/')
def home():
return render_template('home.html')
@app.route('/results',methods=['GET'])
def result():
url = request.args.get('url')
nreviews = int(request.args.get('num'))
clean_reviews = []
org_reviews = []
customernames = []
commentheads = []
ratings = []
with urllib.urlopen(url) as u:
page = u.read()
page_html = BeautifulSoup(page, "html.parser")
proname = page_html.find_all('span', {'class': 'B_NuCI'})[0].get_text()
price = page_html.find_all('div', {'class': '_30jeq3 _16Jk6d'})[0].get_text()
# getting the link of see all reviews button
all_reviews_url = page_html.find_all('div', {'class': 'col JOpGWq'})[0]
all_reviews_url = all_reviews_url.find_all('a')[-1]
all_reviews_url = 'https://www.flipkart.com'+all_reviews_url.get('href')
url2 = all_reviews_url+'&page=1'
# start reading reviews and go to next page after all reviews are read
while True:
x = len(clean_reviews)
# extracting the reviews
extract_all_reviews(url2, clean_reviews, org_reviews,customernames,commentheads,ratings)
url2 = url2[:-1]+str(int(url2[-1])+1)
if x == len(clean_reviews) or len(clean_reviews)>=nreviews:break
org_reviews = org_reviews[:nreviews]
clean_reviews = clean_reviews[:nreviews]
customernames = customernames[:nreviews]
commentheads = commentheads[:nreviews]
ratings = ratings[:nreviews]
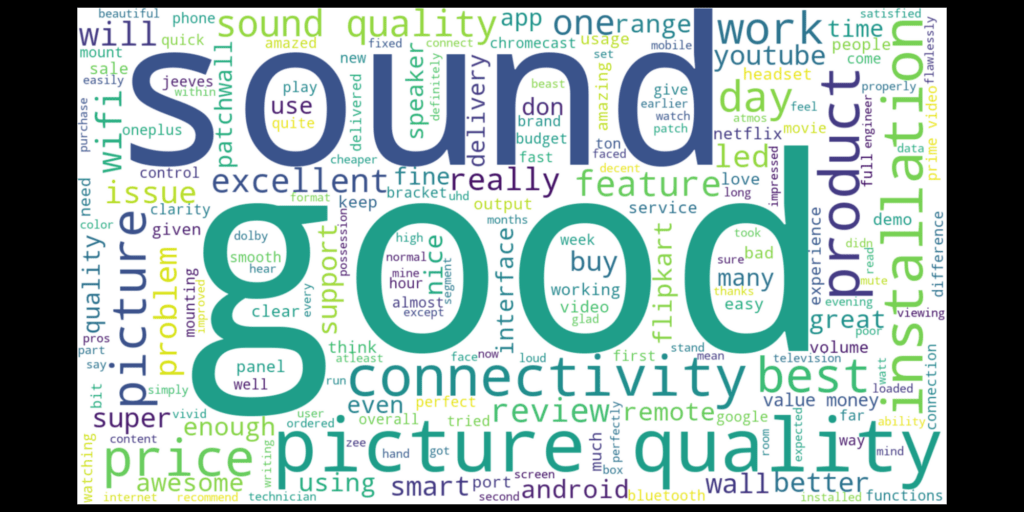
# building our wordcloud and saving it
for_wc = ' '.join(clean_reviews)
wcstops = set(STOPWORDS)
wc = WordCloud(width=1400,height=800,stopwords=wcstops,background_color='white').generate(for_wc)
plt.figure(figsize=(20,10), facecolor='k', edgecolor='k')
plt.imshow(wc, interpolation='bicubic')
plt.axis('off')
plt.tight_layout()
CleanCache(directory='static/images')
plt.savefig('static/images/woc.png')
plt.close()
# making a dictionary of product attributes and saving all the products in a list
d = []
for i in range(len(org_reviews)):
x = {}
x['review'] = org_reviews[i]
# x['sent'] = predictions[i]
x['cn'] = customernames[i]
x['ch'] = commentheads[i]
x['stars'] = ratings[i]
d.append(x)
for i in d:
if i['stars']!=0:
if i['stars'] in [1,2]:
i['sent'] = 'NEGATIVE'
else:
i['sent'] = 'POSITIVE'
np,nn =0,0
for i in d:
if i['sent']=='NEGATIVE':nn+=1
else:np+=1
return render_template('result.html',dic=d,n=len(clean_reviews),nn=nn,np=np,proname=proname,price=price)
@app.route('/wc')
def wc():
return render_template('wc.html')
class CleanCache:
'''
this class is responsible to clear any residual csv and image files
present due to the past searches made.
'''
def __init__(self, directory=None):
self.clean_path = directory
# only proceed if directory is not empty
if os.listdir(self.clean_path) != list():
# iterate over the files and remove each file
files = os.listdir(self.clean_path)
for fileName in files:
print(fileName)
os.remove(os.path.join(self.clean_path,fileName))
print("cleaned!")
if __name__ == '__main__':
app.run(debug=True)
# this was the code for Flipkart Reviews extraction and sentiment analysis
- Line 1-13 – Importing required packages.
- Line 20 – Declaring a Flask app.
- Lie 21 – This line is for preventing caching. (just copy and paste this line)
- Line 24-43 – Function to clean review text.
- Line 46-77 – This function use web scraping to extract all reviews from the page.
- Line 47-49 – Open url and read the whole page in html format using BeautifuSoup.
- Line 50-53 – Extract needed infos like comment, comment head, customer name and rating given.
- Line 55-58 – Adding original reviews and cleaned reviews to lists.
- Line 67-74 – Extract the number given as rating and convert it to int and save it in list ‘ra’.
- Line 80 – We are using app.route(‘/’) which means simply homepage of our web app.
- Line 82 – Show ‘home.html’ on our homepage.
- Line 84-162 – Show scraped reviews on our results page.
- Line 86 – Get the url.
- Line 88 – Get the no. of reviews to examine.
- Line 89-93 – Initialize some values.
- Line 95-97 – Open the url and read the whole html of the page.
- Line 99-100- Extract the product name and its price.
- Line 103- Find the block on page which contains the All Reviews button.

- Line 104- From that block, extract the link of the All Reviews button.
- Line 105- Create the link as ‘https://www.flipkart.com’ + all_reviews_url.get(‘href’) where all_reviews.get(‘href’) will give the link to that all reviews page.

- Line 106- Just adding a page parameter to the link, so that we can easily do the pagination further to read/extract more and more reviews.
- Line 110-115- Read the n no. of reviews.
- Line 113 – Extract all reviews from that page.
- Line 114- Create a link for the next page by just changing 1 to 2 or 2 to 3, etc.
- Line 117-121- Simply take out n no. of extracted data. Our extracted data contains reviews, customer names, stars given by them, and comment heads.
- Line 125-134 – Creating the wordcloud using clean reviews.
- Line 138-146- Creating a list of dictionaries where each dictionary depicts the whole data about a review. One dictionary will contain a comment, comment head, stars given, and the name of the customer.
- Line 149-154 – If the stars given by the user are 1 or 2 then add one more attribute in the dictionary that is ‘sent’ or sentiment and mark it as NEGATIVE else mark it as POSITIVE.
- Line 157-160- Counting positive and negative reviews.
- Line 162- Sending this information to our HTML page.
- Line 165-167 – Show the wordcloud on (‘/wc’).
- Line 170-184 – Just a simple function to prevent caching. (no need to go in depth of it)
- Line 187-188 – Run our app.
Working of our Flipkart Reviews extraction and sentiment analysis app…
Download Source Code for Flipkart Reviews extraction and sentiment analysis …
NOTE – Please note one thing, these class names that Flipkart uses for these elements may change over time, so if the program gives an error in these parts, simply go to the Flipkart page, inspect the element and find the new id of that block/element/link.
Do let me know if there’s any query regarding Flipkart Reviews extraction and sentiment analysis by contacting me on email or LinkedIn. I have tried my best to explain this code.
This Flipkart Reviews extraction and sentiment analysis is a very interesting project and can have further endless use cases also. You can explore more of its use cases by just giving it some time.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time…
Read my previous post: CREDIT CARD FRAUD DETECTION
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.





