Today’s blog is going to be a very short blog where we will see the magic of Words to Vectors using the Spacy library and also we will prove that King-Man+Woman = Queen.
This is going to be a very interesting blog, so without any due, Let’s do it…
Checkout the Video here – https://youtu.be/qxf7TGRLpgg
Step 1 – Importing libraries required for Words to Vectors.
import spacy from scipy import spatial
Step 2 – Load the English medium library.
nlp = spacy.load('en_core_web_md')
nlp.pipe_names
- It means that when spacy loads a string it is passed through this pipeline.
- Tagger, parser, and ner; where ‘ner’ is named entity recognition.
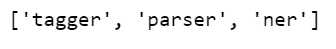
Step 3 – Checking the size of our vocabulary.
# md model --> 685k keys, 20k unique vectors (300 dimensions) # lg model --> 685k keys, 685k unique vectors (300 dimensions) print(len(nlp.vocab)) print(len(nlp.vocab.vectors))
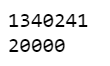
- We have loaded the medium model above in which we have 20000 (20k) unique words/vectors as you can see above.
- Also, we have an option for a Large model in which we have 685000 (685k) unique words/vectors.
Step 4 – Checking the no. of dimensions in our vectors.
nlp(u'lion').vector.shape
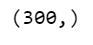
- Checking dimensions of a random word like ‘lion’.
- Every word/vector will have 300 dimensions.
- This means each word will be depicted by a vector of size 300.
Step 5 – Checking some similarities.
tokens = nlp(u'cat lion pet')
for t1 in tokens:
for t2 in tokens:
print(t1.text,t2.text,t1.similarity(t2))

- Let’s create a string, ‘cat lion pet’.
- Now let’s check their inter-relations.
- We can see that the same words have similarity 1 obviously.
- Also, we can see that cat is highly similar to the word pet because most of the time these words are used together.
- Lion is very less similar to a pet because as we know the lion is not a pet and these 2 words are not also used together.
Step 6 – Checking some tokens.
tokens = nlp(u'dog cat sharma abhishek')
for t in tokens:
print(t.text,t.has_vector,t.vector_norm,t.is_oov)
- Let’s create one more string ‘dog cat sharma abhishek’.
- Now let’s traverse in tokens.
- t.has_vector tells us if that word is present in our vocabulary or not, or we can say that it checks if the vector of that word is present in our vocabulary or not.
- t.vector_norm gives us the L2 norm of the token’s vector representation.
- t.is_oov checks if the token is out of vocabulary or not. False means it is in the vocabulary.

Step 7 – Creating Vectors of King, Man, Woman.
# Words to Vectors king = nlp(u'king').vector man = nlp(u'man').vector woman = nlp(u'woman').vector
Step 8 – Performing operation on the vectors.
# creating the new vector new_vector = king-man+woman new_vector
Step 9 – Creating a cosine similarity function.
cosine_similarity = lambda vec1,vec2 : 1-spatial.distance.cosine(vec1,vec2)
Step 10 – Checking the similarity of our new vector with every word in our vocab.
similarities = []
for word in nlp.vocab:
if word.has_vector and word.is_alpha and word.is_lower:
similarities.append((cosine_similarity(new_vector,word.vector),word.text))
- Here we are iterating through each and every word in the vocabulary and calculating its similarity to the new vector, and adding that to a new list called similarities.
Step 11 – Printing the top 10 similar words.
# as we can observe that for a vector like king-man+woman we obviously expect a queen and it
#proves to be successful in getting that
for similarity,word in sorted(similarities,reverse=True)[:10]:
print(word)
- And BOOM here is the top 10 matched words from our vocabulary to the new vector we created.
- We can see that the second word is Queen.
- All other words are also somewhat related as all of them are royal words like a sultan, price, highness, etc.

Download Source Code
Do let me know if there’s any query regarding Words to Vectors using Spacy by contacting me by email or LinkedIn. I have tried my best to explain this code.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time…
Read my previous post: FLIPKART REVIEWS EXTRACTION AND SENTIMENT ANALYSIS USING FLASK APP
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.



I get other results:
king
and
that
havin
where
she
they
woman
somethin
there
no “queen” but many stopwords????
try removing stop words initially.