Hey guys in today’s article we will build a Table Extractor Flask App using Python. We will use the pdfplumber library to fetch the tables from the PDF files. It will be a fun article, so without any further due, let’s do it…
Introducing the Table Extractor Flask App
The Table Extractor Flask App is a web-based application designed to simplify the extraction of tabular data from PDF documents. Leveraging the powerful capabilities of the pdfplumber library, the app offers a user-friendly interface for uploading PDF files and extracting structured data from tables within those documents.
Snapshots
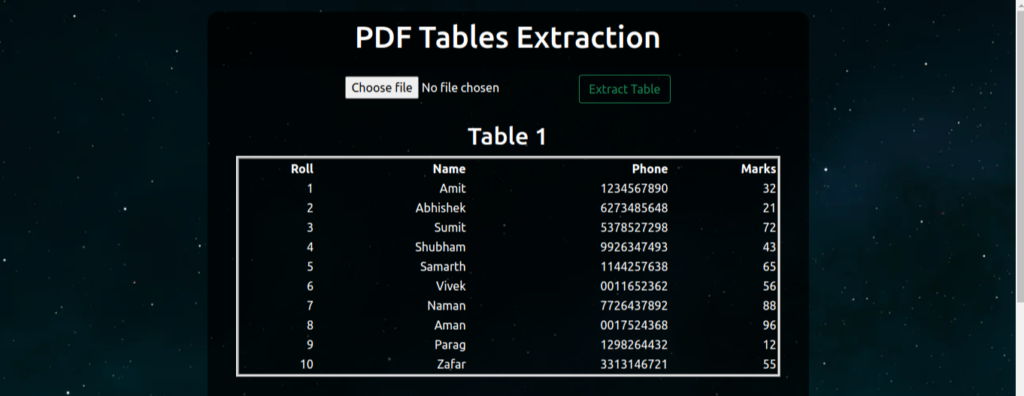
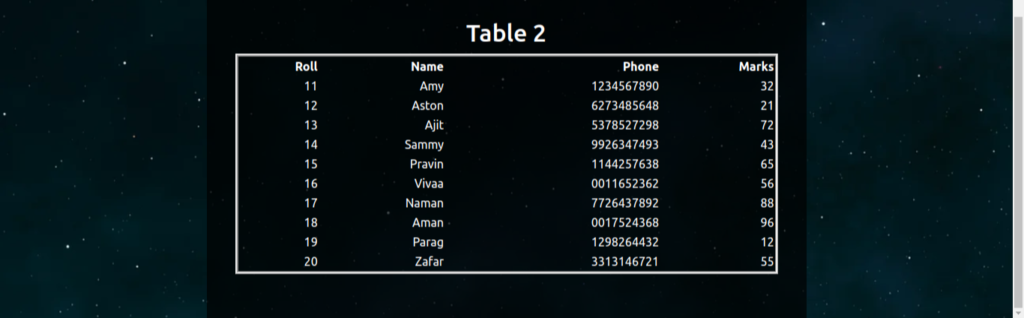
Extracted Tables on the Front End
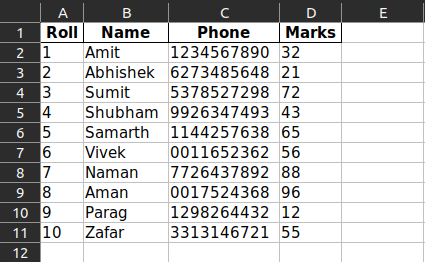
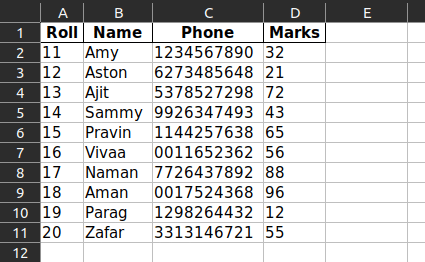
Extracted Tables in the Excel File
Working of our Table Extractor Flask App
- Run the Flask App using the ‘flask run’ command.
- An Interface will open, and upload the PDF File there.
- Click on the ‘Extract Table’ button, and the script will run in the background.
- In the background, the pdfplumber library will search for tables in the given PDF file.
- If any tables are found, they will be converted to HTML format and fed to the front end where they are displayed.
- Also, an Excel file is stored with all the tables extracted.
- And, this is how this application works.
Source Code for Table Extractor Flask App
app.py
import os
from werkzeug.utils import secure_filename
from flask import Flask,request,render_template
import pdfplumber
import pandas as pd
UPLOAD_FOLDER = './static/uploads'
ALLOWED_EXTENSIONS = set(['pdf'])
app = Flask(__name__)
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = 0
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.secret_key = "secret key"
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
def extract(pdf_path):
tables = []
with pdfplumber.open('test.pdf') as pdf:
for page in pdf.pages:
table = page.extract_table()
if table:
table = pd.DataFrame(table)
table.columns = table.iloc[0]
table.drop(0,inplace=True)
tables.append(table)
return tables
@app.route('/')
def home():
return render_template('home.html')
@app.route('/extract_table',methods=['POST'])
def extract_table():
file = request.files['file']
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
tables = extract(UPLOAD_FOLDER+'/'+filename)
with pd.ExcelWriter('extracted_tables.xlsx') as writer:
for i, df in enumerate(tables):
df.to_excel(writer, sheet_name=str(i+1), index=False)
tables = [x.to_html(index=False) for x in tables]
return render_template('home.html',org_img_name=filename,tables=tables,ntables=len(tables))
if __name__ == '__main__':
app.run(debug=True)
home.html
<!doctype html>
<html lang="en">
<style type='text/css'>
body {
background-image: url('https://cdn.pixabay.com/photo/2018/12/18/22/29/background-3883181_1280.jpg');
background-repeat: no-repeat;
background-attachment: fixed;
background-size: cover;
font-family: sans-serif;
margin-top: 40px;
}
.regform {
width: 800px;
background-color: rgb(0, 0, 0, 0.8);
margin: auto;
color: #FFFFFF;
padding: 10px 0px 10px 0px;
text-align: center;
border-radius: 15px 15px 0px 0px;
}
.main-form {
width: 800px;
margin: auto;
background-color: rgb(0, 0, 0, 0.7);
padding-left: 50px;
padding-right: 50px;
padding-bottom: 20px;
color: #FFFFFF;
}
</style>
<head>
<!-- Required meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Bootstrap CSS -->
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta3/dist/css/bootstrap.min.css" rel="stylesheet"
integrity="sha384-eOJMYsd53ii+scO/bJGFsiCZc+5NDVN2yr8+0RDqr0Ql0h+rP48ckxlpbzKgwra6" crossorigin="anonymous">
<title>PDF Tables Extraction</title>
</head>
<body>
<div class='regform mt-3'>
<h1>PDF Tables Extraction</h1>
</div>
<form action='/extract_table' class='main-form' method="POST" enctype="multipart/form-data">
<div class='text-center'>
<input type="file" id="file" name='file' style="margin-top:10px;margin-bottom:10px;">
<button type='submit' class='btn btn-outline-success'> Extract Table
</button>
</div>
</form>
{% if ntables %}
<div class="main-form" style="margin:auto;">
<div class="text-center">
{% for i in range(ntables) %}
<h2>Table {{i+1}}</h2>
<div class="row" style="text-align: right; border: ridge;margin-bottom: 40px;">
{{ tables[i] | safe}}
</div>
{% endfor %}
</div>
</div>
{% endif %}
</body>
</html>
Snapshots
Extracted Tables on the Front End
Extracted Tables in the Excel File
Download the Source Code for the Table Extractor Flask App
Conclusion
The Table Extractor Flask App, powered by the pdfplumber Python library, offers a convenient and efficient solution for extracting tabular data from PDF documents. By automating the extraction process and providing a user-friendly interface, the app streamlines data-handling tasks and enhances productivity.
So in this way you too can build your Table Extractor Flask App using Python. If you have any doubt regarding this, you can contact me by mail.
FAQs
What is the Table Extractor Flask App?
The Table Extractor Flask App is a web-based application designed to extract tabular data from PDF documents. It utilizes the pdfplumber Python library to automatically detect tables within PDF files and extract structured data from them.
How does the app work?
Users can upload PDF documents containing tables to the app. The app then analyzes the documents, identifies table locations, and extracts tabular data using pdfplumber’s table extraction algorithms. Users can choose to export the extracted data in formats like CSV or Excel.
What types of documents does the app support?
The app supports PDF documents containing tables. It can handle various types of tables, including those found in financial reports, research papers, invoices, and legal documents.
Is the extracted data accurate?
While the app employs sophisticated algorithms for table detection and data extraction, the accuracy of the extracted data may vary depending on factors such as the quality and formatting of the input documents. Users can review and validate the extracted data to ensure accuracy.
Read my last article – Words Counter and Paragraphs Counter Flask App using Python
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net





![[Latest] Python for Loops with Examples – Easiest Tutorial – 2026](https://machinelearningprojects.net/wp-content/uploads/2023/05/python-for-loops-1-1024x536.webp)