
So one of the most awaited blogs is finally here. Today we will be building a Movie Recommendation System that will produce very good results in very less lines of code. So without any further due, let’s do it…
First way
Step 1 – Importing packages required for Movie Recommendation System.
import pandas as pd
Step 2 – Reading input data.
df1 = pd.read_csv('u.data',sep='\t')
df1.columns = ['user_id','item_id','rating','timestamp']
df1.head()
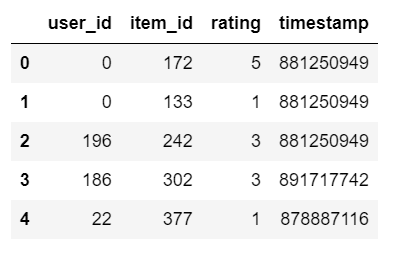
Step 3 – Reading Movie titles.
df2 = pd.read_csv('Movie_Id_Titles')
df2.head()
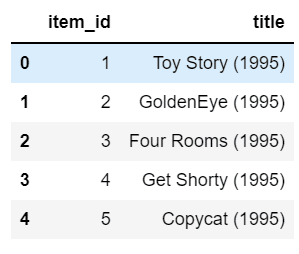
Step 4 – Merging movie data and movie titles.
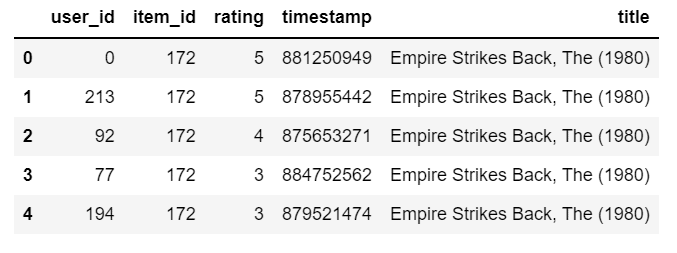
df = pd.merge(df1,df2,on='item_id') df.head()
- We are merging both data frames on ‘item_id’ which is present in both data frames.
Step 5 – Grouping same movie entries.
rating_and_no_of_rating = pd.DataFrame(df.groupby('title')['rating'].mean().sort_values(ascending=False))
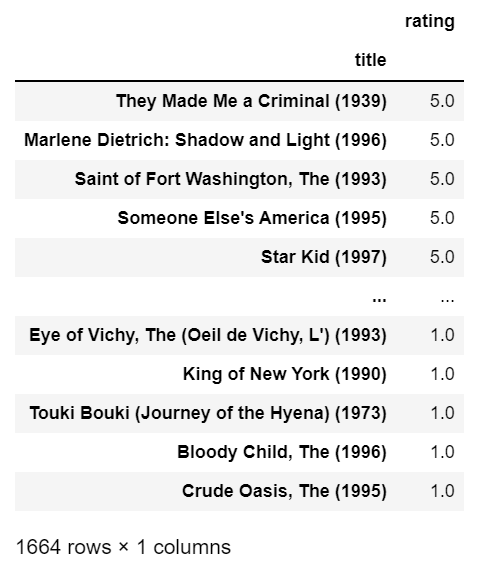
rating_and_no_of_rating
- We are grouping movies here and taking the mean of all ratings given to them and then we are sorting them by their mean rating.
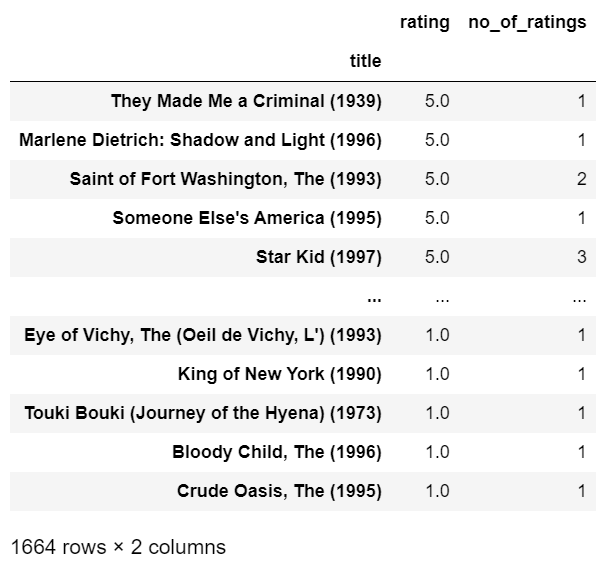
- You can see that in the result below a crap movie ‘They made a criminal’ is showing up which might have got a rating from only one person and that too 5 stars. That’s why its mean is also 5.
Step 6 – Adding a column of no. of ratings.
rating_and_no_of_rating['no_of_ratings'] = df.groupby('title')['rating'].count()
rating_and_no_of_rating
- Adding a column of no. of ratings.
- We are calculating the no. of ratings by using the count method of a data frame.
Step 7 – Sorting on no. of ratings.
rating_and_no_of_rating = rating_and_no_of_rating.sort_values('no_of_ratings',ascending=False)
rating_and_no_of_rating.head()
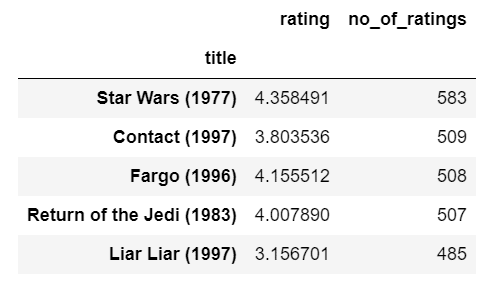
- Simply sort by no. of ratings.
- And now we see some genuine results.
- Star Wars which is a very famous movie has got a mean of 4.35 as a rating from 583 users.
Step 8 – Creating a pivot table.
pt = df.pivot_table(index='user_id',columns='title',values='rating') pt.head()
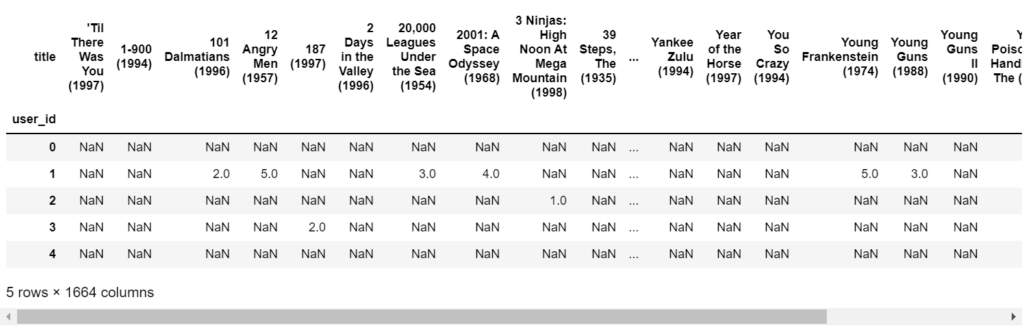
- Creating a pivot table.
- In this pivot table, users go along rows and movies go along columns.
- Nan represents that, that user has not given any rating to that movie.
Step 9 – Checking movie names.
rating_and_no_of_rating.index
- Simply printing all movie names we have.

Step 10 – Live Prediction.
test_movie = input('Enter movie name --> ')
movie_vector = pt[test_movie].dropna()
similar_movies = pt.corrwith(movie_vector)
corr_df = pd.DataFrame(similar_movies,columns=['Correlation'])
corr_df = corr_df.join(rating_and_no_of_rating['no_of_ratings'])
corr_df = corr_df[corr_df['no_of_ratings']>100].sort_values('Correlation',ascending=False).dropna()
corr_df.head(10)
- While testing I added ‘Star Wars (1977)’ as a test movie.
- Pick its vector from the pivot table above.
- Use that vector and correlate it with other movies using corrwith() and it will give its correlation with other movies based on user ratings and store it in similar_movies.
- After that create a data frame as shown below and again merge no_of_ratings in it to take at least 100 ratings as the threshold.
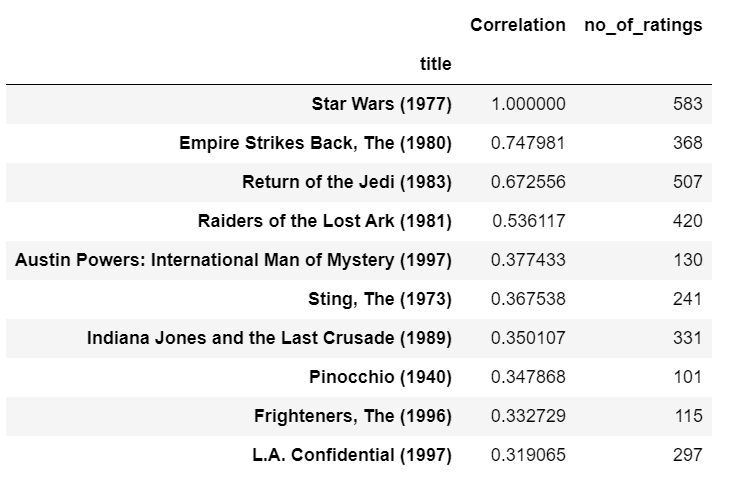
- Sort the results based on correlations and BOOM here are the results.
- We can see the results, all these movies are somehow related to Star Wars.
- Empire Strikes Back, and Return of the Jedi, both of them are related to Star Wars.
Download Source Code and Data for Movie Recommendation System…
Second way
The simple intuition of this 2nd way is that we will be combining the main features like the cast, director, genres, etc., and observe similarities between them because most of the time similar directors make similar movies, similar casts like to perform in some similar specific types of movies.
Step 1 – Importing libraries required for Movie Recommendation System.
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics.pairwise import cosine_similarity
Step 2 – Reading input data.
org_movies = pd.read_csv('movie_dataset.csv')
org_movies.head(3)
Step 3 – Checking columns of our data.
org_movies.columns
Step 4 – Just keep important columns.
movies = org_movies[[ 'genres', 'keywords','cast', 'title', 'director']] movies.head()
- We will remove all the unnecessary columns/features and just keep these 5 columns.
Step 5 – Checking info of our data.
movies.info()
- As we can see from the image below that our data is having some NULL values.
- So we will fill these NULL values in the next step.
Step 6 – Filling Null values.
movies.fillna('',inplace=True)
- We are simply filling the NULL values with an empty space.
Step 7 – Again check the info.
movies.info()
- Now if we check again, we can see that there are no NULL values now.
Step 8 – Make a column called combined features.
movies['combined_features'] = movies['genres'] +' '+ movies['keywords'] +' '+ movies['cast'] +' '+ movies['title'] +' '+ movies['director'] movies.head()
- Here we have made a new column called combined_features which will contain all these features combined or we can say all these strings concatenated.
Step 9 – Observe the first entry in the combined feature column.
movies.iloc[0]['combined_features']
- This is how the first combined_feature looks.
Step 10 – Initializing CountVectorizer.
cv = CountVectorizer() count_matrix = cv.fit_transform(movies['combined_features'])
- Here we are using CountVectorizer() to convert these combined features to a bag of words because we just can’t operate on strings.
Step 11 – Finding similarities between different entries.
cs = cosine_similarity(count_matrix) cs.shape
- Here we are using cosine_similarity to calculate similarities between all the combined features.
- Like we will calculate the similarity between 1st and 2nd combined features, between 2nd and 3rd, between 1st and 3rd, etc.
- And then we come up with this 4803 X 4803 matrix which contains similarities.
Step 12 – Two utility functions.
def get_movie_name_from_index(index):
return org_movies[org_movies['index']==index]['title'].values[0]
def get_index_from_movie_name(name):
return org_movies[org_movies['title']==name]['index'].values[0]
- Just 2 utility functions.
- The first function helps in extracting names from the index.
- The second function helps in extracting the index from the name.
Step 13 – Printing all movie names.
print(list(movies['title']))
Step 14 – Live predictor.
test_movie_name = input('Enter Movie name --> ')
test_movie_index = get_index_from_movie_name(test_movie_name)
movie_corrs = cs[test_movie_index]
movie_corrs = enumerate(movie_corrs)
sorted_similar_movies = sorted(movie_corrs,key=lambda x:x[1],reverse=True)
for i in range(10):
print(get_movie_name_from_index(sorted_similar_movies[i][0]))
- Simply enter the movie name, for eg. ‘The Avengers’.
- Get its index.
- Get its similarities with all other movies using the cosine_similairty matrix.
- Simply enumerate the similarities. This step will just make similarity which was like [0.001, 0.2, 0.65, 0.02…] to [(0,0.001), (1,0.2), (2,0.65), (3,0.02)…]. It will just add an index in front of all of them.
- Then we simply sort the results based on the 2nd parameter above that was similarity (0th index is index and 1st index is a similarity).
- And then print the first 10.
- We can see that it is giving pretty good results as if someone likes ‘The Avengers’, he/she will surely like Avengers: Age of Ultron, Iron Man 2, Captain America, etc.
Download Source Code for Movie Recommendation System…
NOTE – To download data open the following link, right-click and save as.
Download Data for Movie Recommendation System…
Do let me know if there’s any query regarding Movie Recommendation System by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
Read my previous post: IPL SCORE PREDICTION WITH FLASK APP
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.






Hello I hope you’re doing well, first of all I want to thank you for your effort providing this helpful content.
I’ve been facing a little problem, I am not able to donwload the csv data file, if you can help me by sending it via email or any other way I’ll be very thankful.
Best regards.
Hi, I cannot enter to the the second way. The link its broken