So guys, in today’s blog we will see that how we can perform Singular Value Decomposition of some book titles we are having in our dataset using TruncatedSVD. This transformer performs linear dimensionality reduction by means of truncated singular value decomposition (SVD).
Contrary to PCA, this estimator does not center the data before computing the singular value decomposition. This means it can work with sparse matrices efficiently. When we perform SVD (Singular Value Decomposition) on text data it is also called LSA (Latent Semantic Analysis).
So without wasting any time, Let’s do it…
Checkout the video here – https://youtu.be/D3cwjRJOmp8
Step 1 – Importing libraries required for Singular Value Decomposition.
import nltk
from nltk.stem import WordNetLemmatizer
import numpy as np
from sklearn.decomposition import TruncatedSVD
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
nltk.download('punkt')
nltk.download('wordnet')
Step 2 – Reading lines from our text file.
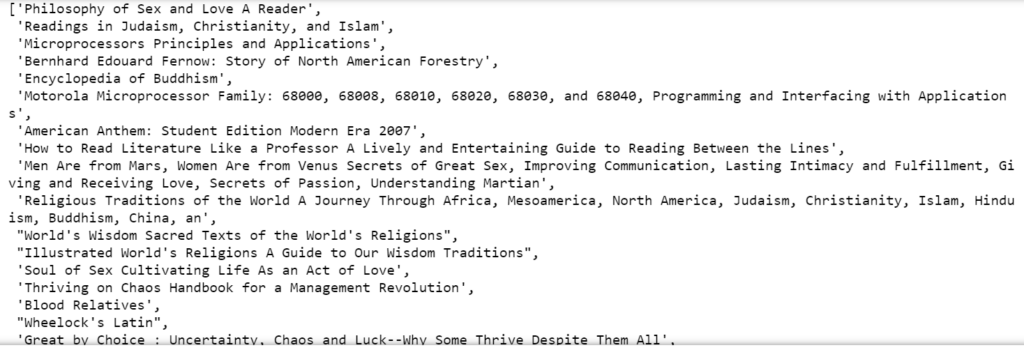
titles = [line.strip() for line in open('all_book_titles.txt')]
titles
Step 3 – Creating a Stopwords set.
stopwords = set(word.strip() for word in open('stopwords.txt'))
stopwords = stopwords.union({
'introduction', 'edition', 'series', 'application',
'approach', 'card', 'access', 'package', 'plus', 'etext',
'brief', 'vol', 'fundamental', 'guide', 'essential', 'printed',
'third', 'second', 'fourth', })
word_lemmatizer = WordNetLemmatizer()
- We have our default stopwords like a, is, that, this, etc. in stopwords.txt. So first of all we are loading all those in a variable called stopwords.
- Secondly, we are adding some more stopwords like edition, introduction, series, etc. manually in the stopwords set. These are some very common words that occur in Book Titles.
- Lastly we are initializing WordNetLemmatizer().
Step 4 – Creating tokenizer function.
def tokenizer(s):
s = s.lower()
tokens = nltk.tokenize.word_tokenize(s)
tokens = [t for t in tokens if len(t)>2]
tokens = [word_lemmatizer.lemmatize(t) for t in tokens]
tokens = [t for t in tokens if t not in stopwords]
tokens = [t for t in tokens if not any(c.isdigit() for c in t)]
return tokens
- This will take a string, convert it to lowercase, tokenize it, remove words having a length less than 2, lemmatize words, remove stopwords and finally remove all those words having any digit in them.
Step 5 – Checking tokenizer.
tokenizer('my name is abhishek and i am 19 years old!!')
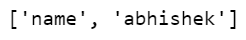
Step 6 – Creating word_2_int and int_2_word dictionaries.
word_2_int = {}
int_2_words = {}
ind = 0
error_count = 0
for title in titles:
try:
title = title.encode('ascii', 'ignore').decode('utf-8') # this will throw exception if bad characters
tokens = tokenizer(title)
for token in tokens:
if token not in word_2_int:
word_2_int[token] = ind
int_2_words[ind]=token
ind += 1
except Exception as e:
print(e)
print(title)
error_count += 1
- We have used try-except because there could be some titles that have some special characters. Those will throw exceptions.
- Then we simply take the title and tokenize it and then simply traverse in those tokens.
- If the token is not in our vocabulary (word_2_int), append it and give a token number to it.
- Similarly, create an apposite dictionary int_2_word also for future use.
- And then simply increment the index.
Step 7 – Creating tokens_2_vectors function.
def tokens_2_vectors(tokens):
X = np.zeros(len(word_2_int))
for t in tokens:
try:
index = word_2_int[t]
X[index]=1
except:
pass
return X
- This function simply converts a title in the token form to a vector.
- It will create an array of our vocabulary size with all elements as 0.
- It will then replace 0s with 1s for the words that are present in the title whose vector we are creating.
Step 8 – Creating a final matrix and fitting it into our SVD.
final_matrix = np.zeros((len(titles),len(word_2_int)))
for i in range(len(titles)):
title = titles[i]
token = tokenizer(title)
final_matrix[i,:] = tokens_2_vectors(token)
svd = TruncatedSVD()
Z = svd.fit_transform(final_matrix)
Z.shape
- Here we are creating a final matrix with rows as no of titles (2373) and columns as no of words in our vocabulary.
- Then we are filling this matrix with vectors of each and every title.
- Finally fitting our TruncatedSVD with our final matrix.
- It means that our data is having 2373 titles and 2 represents the position of that token in the plane.
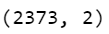
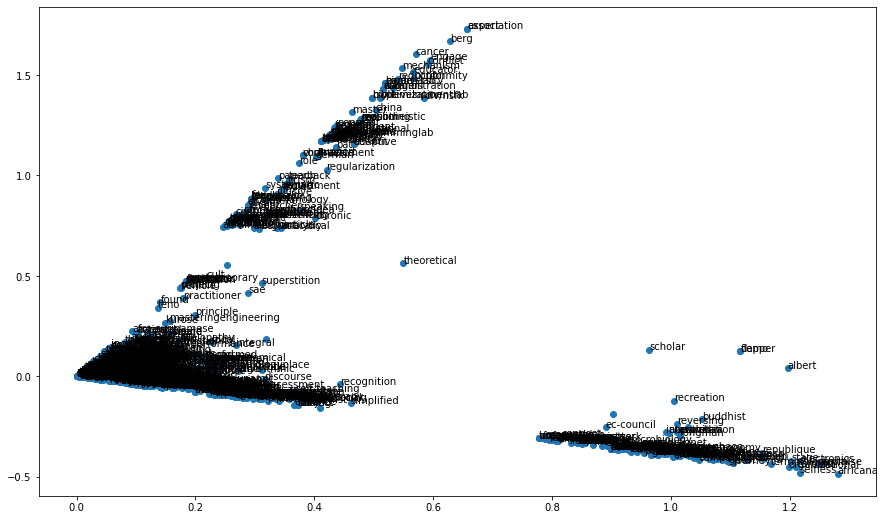
Step 9 – Visualize the results.
fig = plt.figure(figsize=(15,9))
plt.scatter(Z[:,0],Z[:,1])
for i in range(len(word_2_int)):
plt.annotate(int_2_words[i],(Z[i,0],Z[i,1]))
- You will see that similar words will be closer in this plot.
Download Source Code for Singular Value Decomposition…
Do let me know if there’s any query regarding Singular Value Decomposition by contacting me on email or LinkedIn. I have tried my best to explain this code.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
Read my previous post: TOPIC MODELING USING LATENT DIRICHLET ALLOCATION
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.