So guys in today’s blog we will see how we can perform topic modeling using Latent Dirichlet Allocation. What we do in Topic Modeling is try to club together different objects(documents in this case) on the basis of some similar words.
This means that if 2 documents contain similar words, then there is a very high chance that they both might fall under the same category. So without wasting any time, Let’s do it…
Check out the video here – https://youtu.be/a9WGoIiWwXg
Step 1 – Importing required libraries.
import pandas as pd import numpy as np from sklearn.feature_extraction.text import CountVectorizer from sklearn.decomposition import LatentDirichletAllocation
Step 2 – Reading input data.
articles = pd.read_csv('npr.csv')
articles.head()

Step 3 – Checking info of our data.
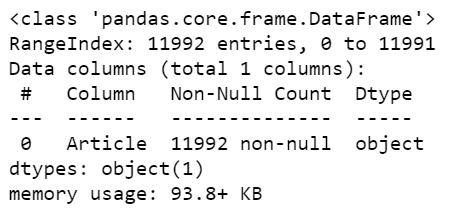
articles.info()
- We can see that our data is having just one column named Article with 11992 entries.
Step 4 – Creating a Document Term Matrix of our data.
cv = CountVectorizer(max_df=0.95,min_df=2,stop_words='english') dtm = cv.fit_transform(articles['Article']) dtm.shape
- Here we are using CountVectorizer to convert our documents to arrays of word counts.
- Here we can see that our dtm is having the shape (11992,54777) where 11992 shows the no. of documents in our dataset and 54777 depicts the no. of distinct words in our total vocabulary.
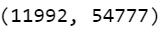
Step 5 – Initializing the Latent Dirichlet Allocation object.
LDA = LatentDirichletAllocation(n_components=7,random_state=42) topic_results = LDA.fit_transform(dtm) LDA.components_.shape
- Let’s initialize the LatentDirichletAllocation object.
- Fit this object on the document term matrix we created above.
- And check its shape.
- We can see that the shape of LDA components is (7,54777) where 7 is the no. of components and 54777 is the size of the vocabulary.
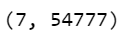
Step 6 – Printing a list of features/words on which clustering will be done.
for i,arr in enumerate(LDA.components_):
print(f'TOP 15 WORDS FOR TOPIC #{i}')
print([cv.get_feature_names()[i] for i in arr.argsort()[-15:]])
print('\n\n')
- arr.argsort() will sort the words on the basis of the probability of the occurrence of that word in the document of that specific topic in ascending order we have taken the last 15 words which means the 15 most probable words that will occur for that topic.
- cv.get_feature_names is just a list of all the words in our corpus
- See, the top 15 words of topic #0 are companies, money, year percent, etc. Looks like it is the financial group.
- Topic #1 seems like a political group.
- Topic #3 seems to be a health topic.
- Topic #6 looks to be an educational group.

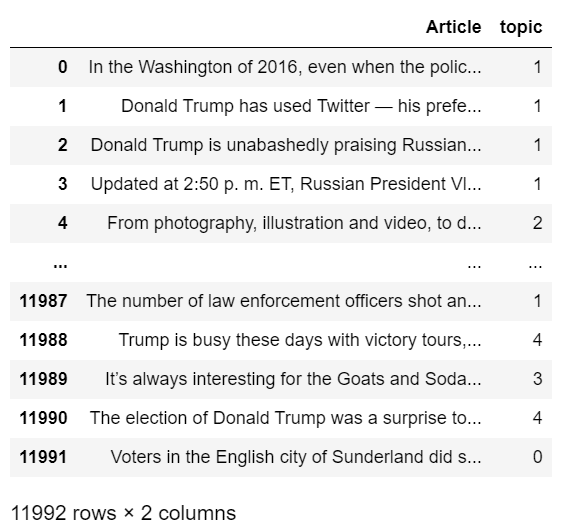
Step 7 – Final results
articles['topic'] = topic_results.argmax(axis=1) articles
- Finally giving topic numbers to documents.
Download the Source Code…
NOTE – For downloading data click on the link below, right-click and hit save-as and save it in your project folder with ‘npr.csv’ name.
Download Data…
Do let me know if there’s any query regarding this topic by contacting me on email or LinkedIn. I have tried my best to explain this code.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time…
Read my previous post: WORDS TO VECTORS USING SPACY – PROVING KING-MAN+WOMAN = QUEEN
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.