
So guys in this blog we will be implementing a Fake news Classifier using LSTM. So without any further due, Let’s do it…
Checkout the video here – https://youtu.be/XcHtSSKE6PI
Step 1 – Importing libraries required for Fake news Classifier.
import re
import nltk
import numpy as np
import pandas as pd
import tensorflow as tf
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from tensorflow.keras.models import Sequential
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import one_hot
from sklearn.metrics import confusion_matrix,accuracy_score
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding,LSTM,Dense,Dropout
nltk.download('stopwords')
Step 2 – Reading input data.
df = pd.read_csv('train.csv')
df.dropna(inplace=True)
df.reset_index(inplace=True)
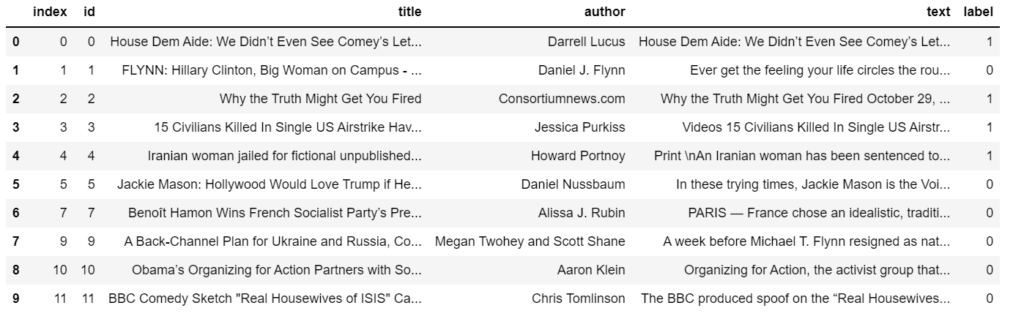
df.head(10)
Step 3 – Creating X and y data.
X = df['title'] y = df['label']
- For X we are just taking the title column.
- For y we are just taking the label column.
Step 4 – Cleaning input data.
ps = PorterStemmer()
corpus = []
for i in range(len(X)):
text = X[i]
text = re.sub('[^a-zA-Z]',' ',text)
text = text.lower()
text = text.split()
text = [ps.stem(t) for t in text if t not in stopwords.words('english')]
corpus.append(' '.join(text))
- Here we are traversing in X and then just simply using regex to clean our data and store it in the corpus list.
- First of all, we are just replacing everything that is not an alphabet with a space.
- Then we are lowercasing it and splitting it.
- Then we are checking if the words are not in stopwords, then stem it.
- Simply join these results and make a sentence out of them and add it to the corpus list.
Step 5 – Encoding input data.
vocab_size = 5000 sent_len = 20 one_hot_encoded = [one_hot(x,vocab_size) for x in corpus] one_hot_encoded = pad_sequences(one_hot_encoded,maxlen=sent_len) one_hot_encoded[0]
- Here we are encoding our text data to numerical data using one_hot.
- Remember this one hot is not that 0s and 1s. In this one-hot encoding, we assign a random number using hashing to the word. The random word is chosen from the range 0-vocab_size.
- Then we are padding the sequences with 0s to make every line of the same length.
- And then simply we are checking how our first sentence looks like after these 2 operations.
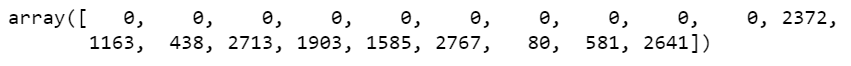
Step 6 – Processing X and y data.
X = np.array(one_hot_encoded) y = np.array(y) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
- Converting X and y to NumPy arrays and simply splitting the data using traintestsplit.
Step 7 – Creating the model.
no_of_output_features = 40 model = Sequential() model.add(Embedding(vocab_size,no_of_output_features,input_length=sent_len)) model.add(Dropout(0.5)) model.add(LSTM(100)) model.add(Dropout(0.5)) model.add(Dense(1)) model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy']) model.summary()
- Here we are creating our model.
- Our model has just 4 layers.
- The first layer is the Embedding layer which will convert the number array which we saw above into a vector of 40 dimensions followed by a Dropout layer.
- And then we have an LSTM layer with 100 nodes followed by a Dropout layer.
- Dropout layers are for preventing Overfitting.

Step 8 – Training the Fake news Classifier model.
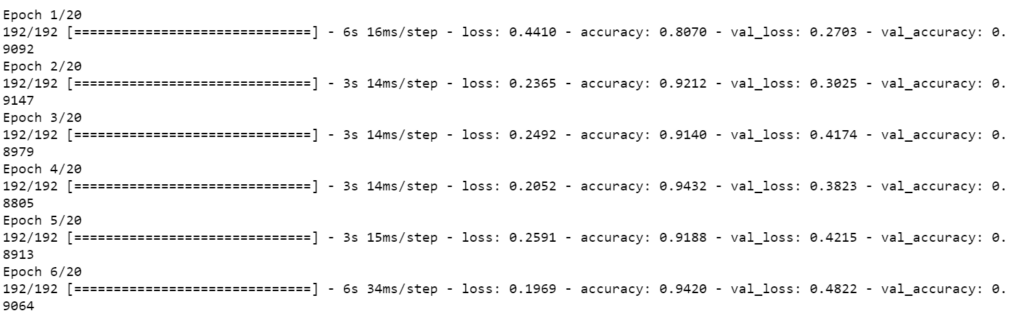
model.fit(X_train,y_train,validation_data=(X_test,y_test),batch_size=64,epochs=40)
Step 9 – Checking metrics of the model.
pred = model.predict_classes(X_test) confusion_matrix(y_test,pred)
- Here in this step we are just printing the Confusion Matrix to check the performance of our model.
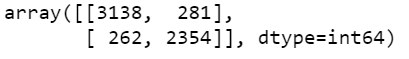
Step 10 – Checking the accuracy of the Fake news Classifier model.
accuracy_score(y_test,pred)
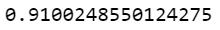
Download the Source Code and Data
Download Source Code for Fake news Classifier…
NOTE – Download train.csv from the link below and place it in the project folder.
Download Fake news Classifier Data…
Do let me know if there’s any query regarding this topic by contacting me on email or LinkedIn. I have tried my best to explain this code.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
Read my previous post: SINGULAR VALUE DECOMPOSITION
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net


train.csv file is deleted please fix link