
In today’s blog, we will see how we can perform Bank Note Authentication or how we can classify Bank Notes into fake or authentic classes based on numeric features like variance, skewness, kurtosis, and entropy. This is going to be a very short blog, so without any further due, Let’s do it…
Code for Bank Note Authentication…
import pandas as pd
import pickle
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
df = pd.read_csv('data/BankNote_Authentication.csv')
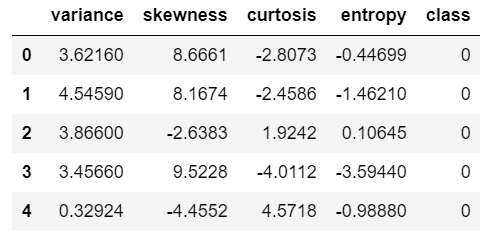
print(df.head())
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
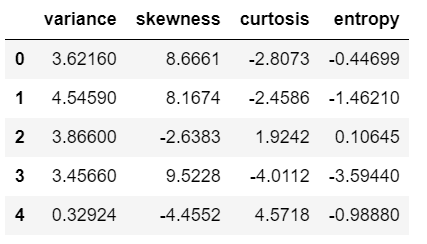
print(X.head())
print(y.head())
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
rf = RandomForestClassifier()
rf.fit(X_train,y_train)
pred = rf.predict(X_test)
score = accuracy_score(y_test,pred)
print(score)
with open('classifier.pkl','wb') as file:
pickle.dump(rf,file)
print('Model saved!!!')
#Let's test a random set of values
print(rf.predict([[-2,-3,1,1]]))
- Line 1-5 – Importing required libraries.
- Line 7 – Reading the whole data which is in csv form.
- Line 9 – Let’s see the head of our data.
- Line 11 – Select all the rows and all columns except the last column as X_train.
- Line 12 – Select all rows and last column as y_train.
- Line 14 – Let’s see the X data.
- Line 15 – Let’s see the y data.

- Line 17 – Splitting the data in 70-30 proportions. 70% data is kept for training and 30% for testing.
- Line 19 – Create a Random Forest Classifier model.
- Line 20 – Fit the training data into our Bank Note Authentication classifier.
- Line 22 – Let’s make predictions on test data to see how our model is performing.
- Line 24 – Let’s calculate the score by comparing our predictions on test data with true labels.
- Line 26 – Printing the score/accuracy on test data.
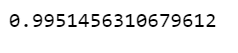
- Line 28-29 – Create a file ‘classifier.pkl’ and save our model in it, so that we can use it in future.
- Line 33-34 – Let’s make a prediction on a random set of values.
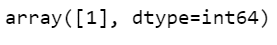
Download the Source Code…
Do let me know if there’s any query regarding Bank Note Authentication by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
Read my previous post: HOW TO FIND THE MOST DOMINANT COLORS IN AN IMAGE IN PYTHON USING KMEANS CLUSTERING
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.





