
In today’s blog, we will build an IPL Score Prediction model using Ridge Regression which is just an upgraded form of Linear Regression. We have the IPL data from 2008 to 2017.
We will also be building a beautiful-looking GUI using HTML and CSS, so without any further due, Let’s do it…
Create a conda environment and install the required libraries
conda create -n ipl python=3.9 conda activate ipl pip install joblib numpy sklearn flask flask run
Step 1 – Importing libraries required for IPL Score Prediction.
import joblib import numpy as np import pandas as pd import seaborn as sns from datetime import datetime from sklearn.linear_model import Ridge from sklearn.preprocessing import StandardScaler from sklearn.model_selection import RandomizedSearchCV from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
Step 2 – Reading the data for IPL Score Prediction.
df = pd.read_csv('ipl.csv')
df.head()

Step 3 – Dropping unnecessary columns.
cols_to_drop = ['mid','batsman','bowler','striker','non-striker'] df.drop(cols_to_drop,axis=1,inplace=True) df.head()
- In our specific use case features like mid, batsman, bowler, striker, and non-striker would not play a great role so it’s better to drop them.
- I know that batsmen can play a role in changing scores, but the problem is that there are tonnes of batsmen that have played in IPL so we can’t operate on these many categories, so it’s better to drop them.

Step 4 – Preprocessing our data for IPL Score Prediction.
df['date'] = df['date'].apply(lambda x: datetime.strptime(x,'%Y-%m-%d'))
# we have to remove temporary teams or the teams which are not available now
consistent_teams = ['Chennai Super Kings', 'Delhi Daredevils',
'Kings XI Punjab', 'Kolkata Knight Riders',
'Mumbai Indians', 'Rajasthan Royals',
'Royal Challengers Bangalore', 'Sunrisers Hyderabad']
df = df[(df['bat_team'].isin(consistent_teams)) & (df['bowl_team'].isin(consistent_teams))]
# we don't want first five overs data
df = df[df['overs']>=5.0]
df.head()
- Convert the date column to the pandas DateTime column.
- Then we have to remove teams that are not playing today in IPL and we just have to keep consistent teams.
- Also, we will take data that is after the 5 overs because the initial stages of the match do not play that much important part in deciding the score.

Step 5 – Checking unique venues.
df['venue'].unique()
- Checking unique venues.
- We can see that there are some foreign grounds also, so we will remove them in the next step.
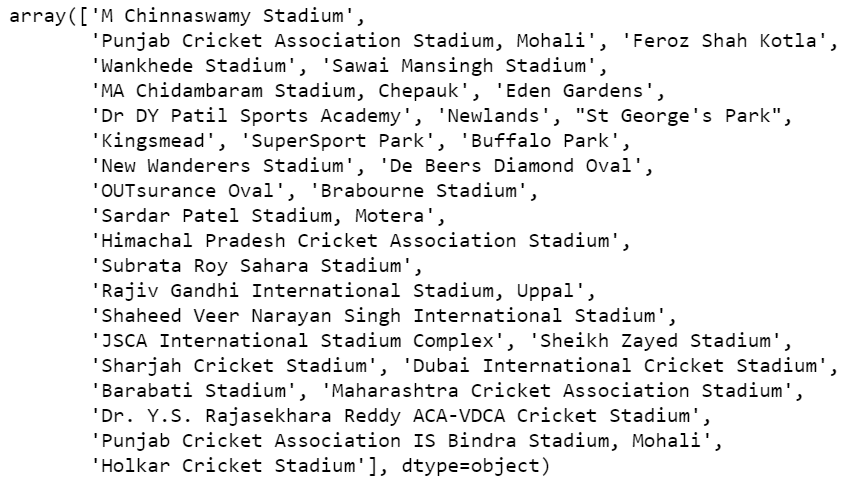
Step 6 – Correct the names of the venues.
def f(x):
if x=='M Chinnaswamy Stadium':
return 'M Chinnaswamy Stadium, Bangalore'
elif x=='Feroz Shah Kotla':
return 'Feroz Shah Kotla, Delhi'
elif x=='Wankhede Stadium':
return 'Wankhede Stadium, Mumbai'
elif x=='Sawai Mansingh Stadium':
return 'Sawai Mansingh Stadium, Jaipur'
elif x=='Eden Gardens':
return 'Eden Gardens, Kolkata'
elif x=='Dr DY Patil Sports Academy':
return 'Dr DY Patil Sports Academy, Mumbai'
elif x=='Himachal Pradesh Cricket Association Stadium':
return 'Himachal Pradesh Cricket Association Stadium, Dharamshala'
elif x=='Subrata Roy Sahara Stadium':
return 'Maharashtra Cricket Association Stadium, Pune'
elif x=='Shaheed Veer Narayan Singh International Stadium':
return 'Raipur International Cricket Stadium, Raipur'
elif x=='JSCA International Stadium Complex':
return 'JSCA International Stadium Complex, Ranchi'
elif x=='Maharashtra Cricket Association Stadium':
return 'Maharashtra Cricket Association Stadium, Pune'
elif x=='Dr. Y.S. Rajasekhara Reddy ACA-VDCA Cricket Stadium':
return 'ACA-VDCA Stadium, Visakhapatnam'
elif x=='Punjab Cricket Association IS Bindra Stadium, Mohali':
return 'Punjab Cricket Association Stadium, Mohali'
elif x=='Holkar Cricket Stadium':
return 'Holkar Cricket Stadium, Indore'
elif x=='Sheikh Zayed Stadium':
return 'Sheikh Zayed Stadium, Abu-Dhabi'
elif x=='Sharjah Cricket Stadium':
return 'Sharjah Cricket Stadium, Sharjah'
elif x=='Dubai International Cricket Stadium':
return 'Dubai International Cricket Stadium, Dubai'
elif x=='Barabati Stadium':
return 'Barabati Stadium, Cuttack'
else:
return x
ignored_stadiums = ['Newlands', "St George's Park",
'Kingsmead', 'SuperSport Park', 'Buffalo Park',
'New Wanderers Stadium', 'De Beers Diamond Oval',
'OUTsurance Oval', 'Brabourne Stadium']
df = df[True^(df['venue'].isin(ignored_stadiums))]
df['venue'] = df['venue'].apply(f)
df.head()
- Here we are just using this function to correct the venue names.
- After that, we are removing entries in which we have foreign grounds like Newlands, St George’s Park, etc.
- In the third last line, we are using XOR operation to remove these grounds.
- As we know True xor True is False, that’s what we are doing here. If we come across any entry whose venue is in ignored stadiums that entry will be true and true XOR true will become false and we will not take that in df.

Step 7 – Converting categorical columns to dummy variables.
df_new = pd.get_dummies(data=df,columns=['venue','bat_team','bowl_team']) df_new.head()
- Creating dummy variables out of categorical variables like venue, bat_team, and bowl_team.

Step 8 – Checking columns.
df_new.columns

Step 9 – Just change the positions of the columns.
df_new = df_new[['date','venue_ACA-VDCA Stadium, Visakhapatnam',
'venue_Barabati Stadium, Cuttack', 'venue_Dr DY Patil Sports Academy, Mumbai',
'venue_Dubai International Cricket Stadium, Dubai',
'venue_Eden Gardens, Kolkata', 'venue_Feroz Shah Kotla, Delhi',
'venue_Himachal Pradesh Cricket Association Stadium, Dharamshala',
'venue_Holkar Cricket Stadium, Indore',
'venue_JSCA International Stadium Complex, Ranchi',
'venue_M Chinnaswamy Stadium, Bangalore',
'venue_MA Chidambaram Stadium, Chepauk',
'venue_Maharashtra Cricket Association Stadium, Pune',
'venue_Punjab Cricket Association Stadium, Mohali',
'venue_Raipur International Cricket Stadium, Raipur',
'venue_Rajiv Gandhi International Stadium, Uppal',
'venue_Sardar Patel Stadium, Motera',
'venue_Sawai Mansingh Stadium, Jaipur',
'venue_Sharjah Cricket Stadium, Sharjah',
'venue_Sheikh Zayed Stadium, Abu-Dhabi',
'venue_Wankhede Stadium, Mumbai','bat_team_Chennai Super Kings',
'bat_team_Delhi Daredevils', 'bat_team_Kings XI Punjab',
'bat_team_Kolkata Knight Riders', 'bat_team_Mumbai Indians',
'bat_team_Rajasthan Royals', 'bat_team_Royal Challengers Bangalore',
'bat_team_Sunrisers Hyderabad','bowl_team_Chennai Super Kings',
'bowl_team_Delhi Daredevils', 'bowl_team_Kings XI Punjab',
'bowl_team_Kolkata Knight Riders', 'bowl_team_Mumbai Indians',
'bowl_team_Rajasthan Royals', 'bowl_team_Royal Challengers Bangalore',
'bowl_team_Sunrisers Hyderabad','runs', 'wickets', 'overs', 'runs_last_5', 'wickets_last_5',
'total']]
df_new.head()

Step 10 – Resetting index.
df_new.reset_index(inplace=True)
df_new.drop('index',inplace=True,axis=1)
df_new
- See in the image above that indices are not proper because we dropped many entries.
- So we are just resetting indexes in this step and just deleting the index column that it will make of previous indexes.

Step 11 – Scaling our numerical data for the IPL Score Prediction model.
scaler = StandardScaler() scaled_cols = scaler.fit_transform(df_new[['runs', 'wickets', 'overs', 'runs_last_5', 'wickets_last_5']]) scaled_cols = pd.DataFrame(scaled_cols,columns=['runs', 'wickets', 'overs', 'runs_last_5', 'wickets_last_5']) df_new.drop(['runs', 'wickets', 'overs', 'runs_last_5', 'wickets_last_5'],axis=1,inplace=True) df_new = pd.concat([df_new,scaled_cols],axis=1) df_new.head()
- Scaling our columns like ‘runs’, ‘wickets’, ‘overs’, ‘runs_last_5’, ‘wickets_last_5’ to bring them all down to same scale.
- We will not scale the whole data because other columns are just 1s and 0s and this represents categorical columns and we know scaling is just done on numerical values.

Step 12 – Splitting data for training and testing.
X_train = df_new.drop('total',axis=1)[df_new['date'].dt.year<=2016]
X_test = df_new.drop('total',axis=1)[df_new['date'].dt.year>=2017]
X_train.drop('date',inplace=True,axis=1)
X_test.drop('date',inplace=True,axis=1)
y_train = df_new[df_new['date'].dt.year<=2016]['total'].values
y_test = df_new[df_new['date'].dt.year>=2017]['total'].values
- We are splitting using the date column.
- All the data from 2007-2017 is for training.
- Data from and after 2017 is for testing.
Step 13 – Checking our X_train.
X_train

Step 14 – Training our Ridge model for IPL Score Prediction.
ridge = Ridge()
parameters={'alpha':[1e-15,1e-10,1e-8,1e-3,1e-2,1,5,10,20,30,35,40]}
ridge_regressor = RandomizedSearchCV(ridge,parameters,cv=10,scoring='neg_mean_squared_error')
ridge_regressor.fit(X_train,y_train)
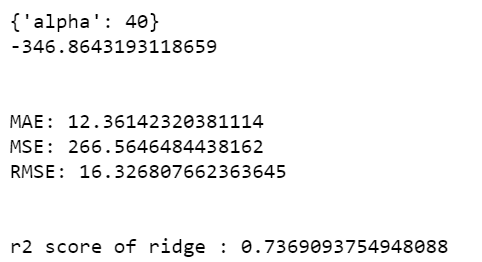
print(ridge_regressor.best_params_)
print(ridge_regressor.best_score_)
print('\n')
# IPL Score Prediction
prediction_r = ridge_regressor.predict(X_test)
print('MAE:', mean_absolute_error(y_test, prediction_r))
print('MSE:', mean_squared_error(y_test, prediction_r))
print('RMSE:', np.sqrt(mean_squared_error(y_test, prediction_r)))
print('\n')
print(f'r2 score of ridge : {r2_score(y_test,prediction_r)}')
sns.distplot(y_test-prediction_r)
- I also tried Linear regression but that was overfitting to the next level, that’s why I went with Ridge Regression because it prevents our model from overfitting.
- Lasso was also giving similar results.

Step 15 – Saving our IPL Score Prediction model.
joblib.dump(ridge_regressor,'iplmodel_ridge.sav')
Working Video of our IPL Score Prediction App…
Download Source Code and Data for IPL Score Prediction…
Do let me know if there’s any query regarding the IPL Score Prediction project by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time …
Read my previous post: HOUSE PRICE PREDICTION – USA HOUSING DATA
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.
Can i use this project
To submit in my college
Sure, Go ahead…
Can we have documentation link for this project?
Sorry, I don’t have anything like that at the moment…
Can we please have the documentation link for this project?
Sorry, there is nothing like that as of now, at least to my knowledge…
I will be thankful if you could please share the IPL Score Prediction… dataset. thank you
https://github.com/sharmaji27/IPL-Score-Predictor/blob/master/ipl.csv