
In today’s blog, we will see how we can perform Spam detection in the simplest way possible with the help of a Count Vectorizer and Multinomial Naive Bayes algorithm. This is going to be a very fun project. So without any further due, Let’s do it…
Checkout the video here – https://youtu.be/hc70yiJUsc4
Step 1 – Importing libraries required for Spam detection.
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.naive_bayes import MultinomialNB from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer from sklearn.model_selection import train_test_split from wordcloud import WordCloud %matplotlib inline
Step 2 – Reading the SMS data.
sms = pd.read_csv('spam.csv',encoding='ISO-8859-1')
sms.head()
- We have passed encoding=’ISO-8859-1′ so that it can tackle special characters like emojis also.

Step 3 – Delete the unnecessary columns.
cols_to_drop = ['Unnamed: 2','Unnamed: 3','Unnamed: 4'] sms.drop(cols_to_drop,axis=1,inplace=True) sms.columns = ['label','message'] sms.head()

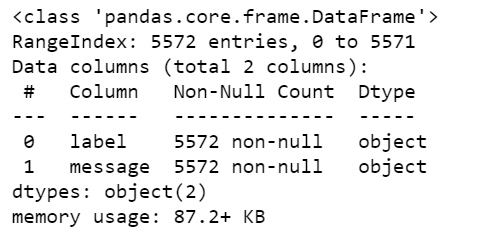
Step 4 – Checking the info of our SMS data.
sms.info()
Step 5 – Declaring Count Vectorizer.
cv = CountVectorizer(decode_error='ignore') X = cv.fit_transform(sms['message']) X_train, X_test, y_train, y_test = train_test_split(X, sms['label'], test_size=0.3, random_state=101)
- Count Vectorizer simply creates a Bag of words. In Bag of words, all the words in the vocabulary go along columns and documents go along rows.
- Each row depicts one message.
- Then we are simply splitting our data into training and testing data.
sms['message'][0]
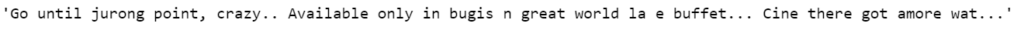
Step 6 – Creating a Multinomial Naive Bayes model for Spam detection.
mnb = MultinomialNB()
mnb.fit(X_train,y_train)
print('training accuracy is --> ',mnb.score(X_train,y_train)*100)
print('test accuracy is --> ',mnb.score(X_test,y_test)*100)
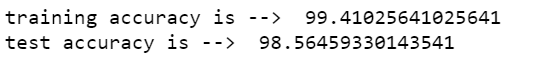
- Here we are just declaring Multinomial NB.
- Naive Bayes works best on text data because of its naive assumption that features are independent of each other.
Step 7 – Visualizing the results.
def visualize(label):
words = ''
for msg in sms[sms['label']==label]['message']:
msg = msg.lower()
words+=msg + ' '
wordcloud = WordCloud(width=600,height=400).generate(words)
plt.imshow(wordcloud)
plt.axis('off')
- This is just a function that creates a wordcloud for all the words in spam and ham categories.
- This is just a function that creates a wordcloud for all the words in spam and ham categories.
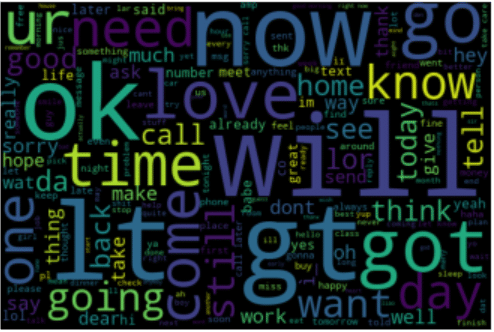
- Bigger words in wordcloud depict their high frequency.
- The bigger the words, the more it occurs.
- Smaller the word, the lesser it occurs.
visualize('spam')

NOTE – Like here free is the biggest word, and as we know that messages containing free words are mostly SPAM.
visualize('ham')
Step 8 – Live Spam detection.
# just type in your message and run
your_message = 'You are the lucky winner for the lottery price of $6million.'
your_message = cv.transform([your_message])
claass = mnb.predict(your_message)
print(f'This is a {claass[0]} message')

- Just type in your message in ‘your_message’ and run this cell and it will try its best to classify it as either spam or ham.
Download Source Code for Spam detection …
Do let me know if there’s any query regarding Spam detection by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
Read my previous post: PREDICTING THE TAX OF A HOUSE USING RANDOM FOREST – BOSTON HOUSING DATA
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.





