
Hey guys, So here comes the ninth blog of the Handwritten notes series which we started. We will be talking about Decision Trees in this blog. I have uploaded my handwritten notes below and tried to explain them in the shortest and best way possible.
The first blog of this series was NumPy Handwritten Notes and the second was Pandas Handwritten Notes. If you haven’t seen those yet, go check them out.
Let’s go through the Decision Trees notes…
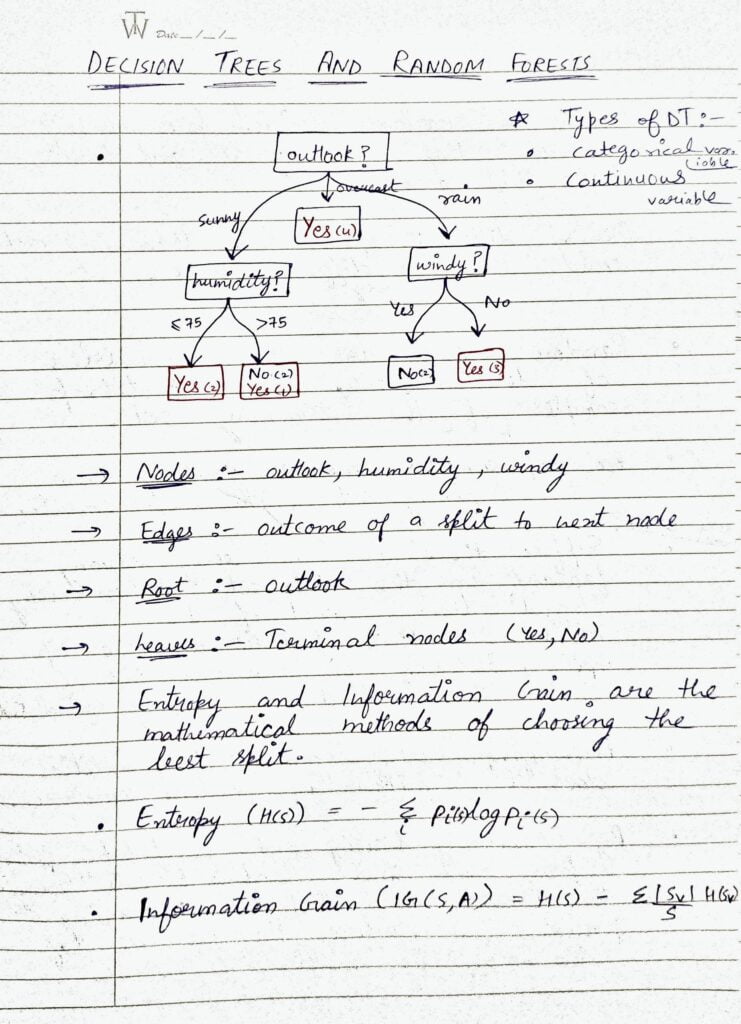
- In the shown Decision Tree, the outlook is the root node, humidity and windy are nodes, sunny, overcast, and rainy are the edges, and Yes’s and No’s are leaves or leaf nodes.
- At every level, we try to split our decision tree on that attribute which is giving the highest information gain or we can say that split on that attribute which is minimizing the entropy of the next level as compared to the current level.
- I have given the formula for Entropy. You will notice that this is something that we use while binary-cross-entropy loss function.
- And then there is the formula for Information Gain which is simply the Entropy of previous level-Current Entropy.

- Due to high Variance, Decision Trees does not perform that much great and does not give high accuracy.
- Means different splits into training data could lead to very different splits.
- That’s where Random Forests come into play.
- Random Forests are the ensembles of Decision Trees using bootstrap samples of the training data. Bootstrap samples mean taking random rows and random columns from data with replacement. Usually, you would have seen that we just take random rows. But here we are also picking columns randomly.
- This is done to build different Decision Trees. Suppose there is a very strong feature in the dataset and every time while building various Decision Trees in Random Forests every DT will pick that feature as the root node and all the trees will be almost similar and will become somehow correlated. That’s why to remove this correlation, we pick columns/features randomly.
- In this way, we end up with different Decision Trees, and averaging them can now really reduce Variance.

- We can train and make predictions from Decision Trees and Random Forests by simply importing them from the sklearn library.
- Decision Trees use the ID3 algorithm which uses the concept of Entropy and Information Gain. It uses the top-down greedy approach to build trees.
- Ther is one more CART algorithm which uses the Gini index to build trees.
Do let me know if there’s any query regarding Decision Trees by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
READ MY PREVIOUS BLOG: K-NEAREST NEIGHBORS (KNN)- LAST-MINUTE NOTES
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.





