
Hey guys, So here comes the seventh blog of the Handwritten notes series which we started. We will be talking about Logistic Regression in this blog. I have uploaded my handwritten notes below and tried to explain them in the shortest and best way possible.
The first blog of this series was NumPy Handwritten Notes and the second was Pandas Handwritten Notes. If you haven’t seen those yet, go check them out.
Let’s go through the Logistic Regression notes…
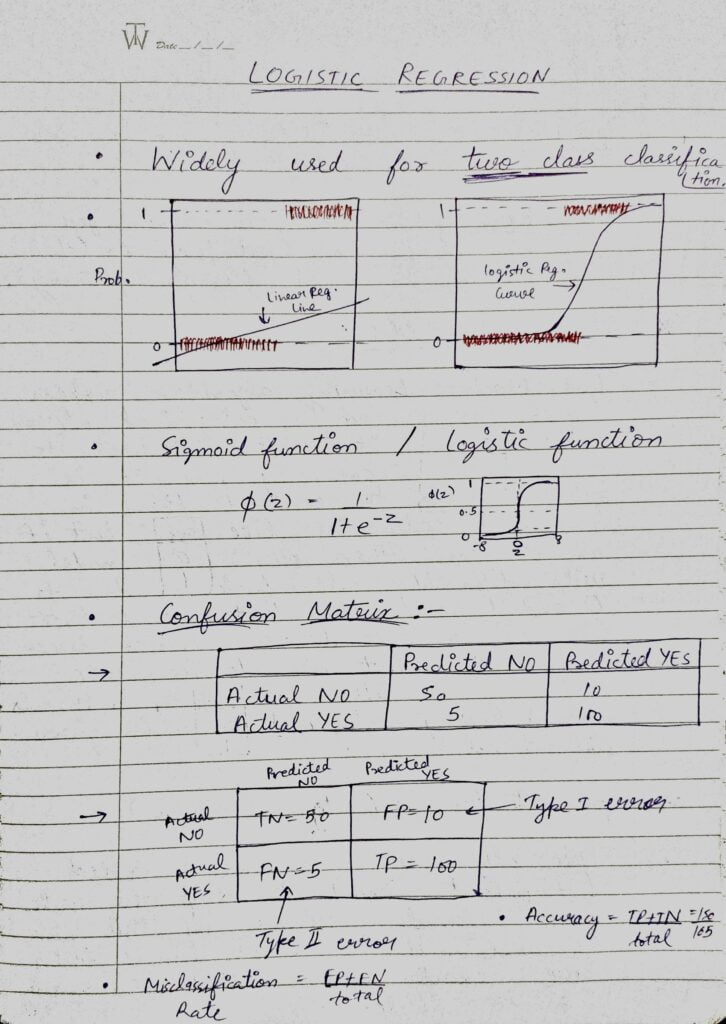
- Logistic regression is a supervised learning binary classification algorithm.
- It is used to predict the probability of a target variable.
- It is one of the simplest ML algorithms that can be used for various classification problems such as spam detection, Diabetes prediction, cancer detection, etc.
- It can also be thought of as the classification version of Linear Regression that uses a special S-shaped curve known as the Sigmoid function.
- Logistic Regression can also be thought of as a smaller instance of a Neural Network because it uses Sigmoid Function which adds non-linearity to our linear function.
- Sigmoid function is a saturated function as it can’t go above 1 and can’t go below 0.
- After that I have shown a Confusion Matrix.
- A confusion matrix is a technique for summarizing the performance of a classification algorithm.
- In confusion matrix, there are 2 types of errors, Type 1 error or False Positives and Type 2 error or False Negatives.

- Example of Type 1 error is Telling a man that you are pregnant.
- Example of Type 2 error is Telling a woman, you are not pregnant (when she is having 8 months big tummy).
- Then we are talking about Dummy Variables. We use Dummy variables when we are dealing with the categorical columns. Our Machine Learning algorithms only understand numbers and values like ‘male’ or ‘female’ does not make any sense to it.
- Thats why we need to convert them to numbers. What we do is we create dummy columns out of this column. Like in this case we will crete 2 new columns in our dataset. One will be ‘sex_male’ and other will be ‘sex_female’.
- To make it more efficient and reduce redundancy, what we do is we drop 1 column. Because if ‘sex_female’ is 0, it will obviously be male. We dont need ‘sex_male’=1 here.
- We use pd.get_dummies(column name) to create dummy columns and after that we join these dummy columns with main dataframe.
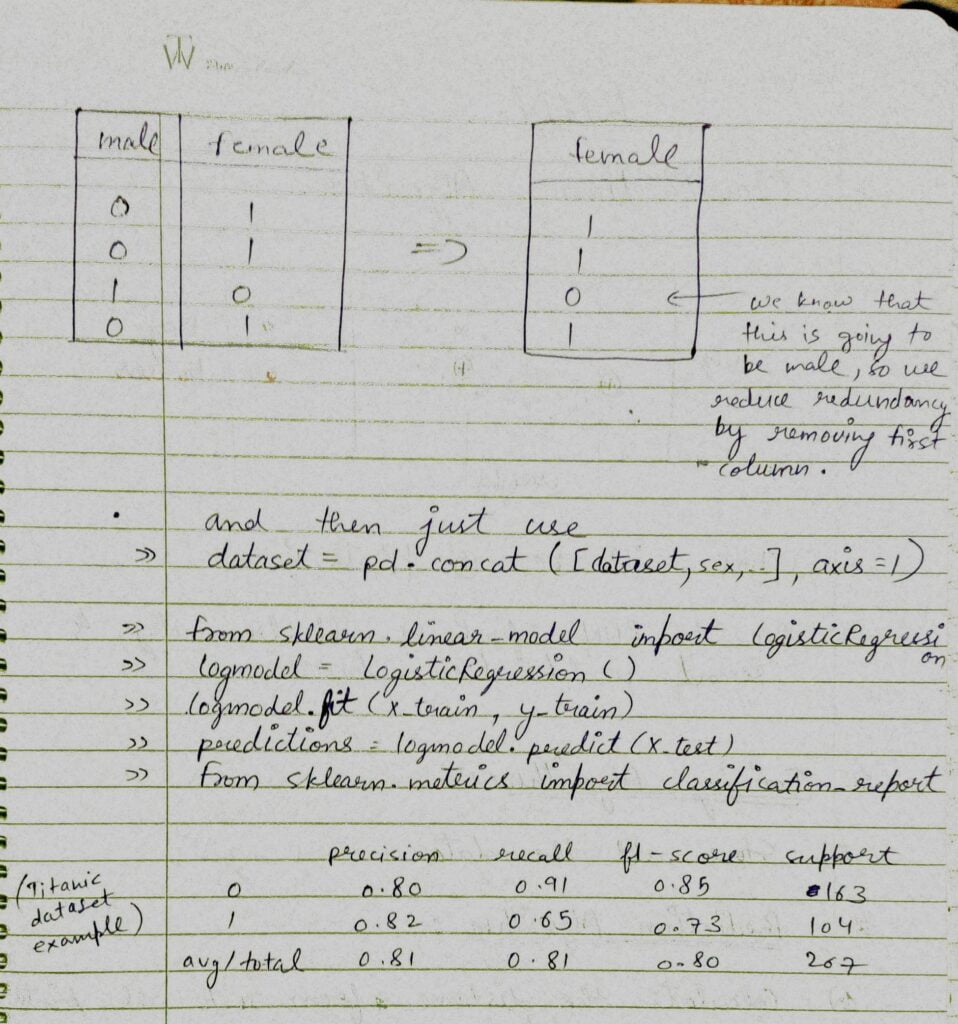
- Here we are getting the dummy variables and simply concating it with the main dataframe.
- After that we are just training our Logistic Regression model.
- In the last we have shown the classification report of the trained model.
Do let me know if there’s any query regarding Logistic Regression by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
READ MY PREVIOUS BLOG: BIAS VARIANCE TRADEOFF – LAST-MINUTE NOTES
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.





