
Hey guys, So here comes the sixth blog of the Handwritten notes series which we started. We will be talking about Bias Variance TradeOff in this blog. I have uploaded my handwritten notes below and tried to explain them in the shortest and best way possible.
The first blog of this series was NumPy Handwritten Notes and the second was Pandas Handwritten Notes. If you haven’t seen those yet, go check them out.
Let’s go through the Bias Variance Tradeoff notes…
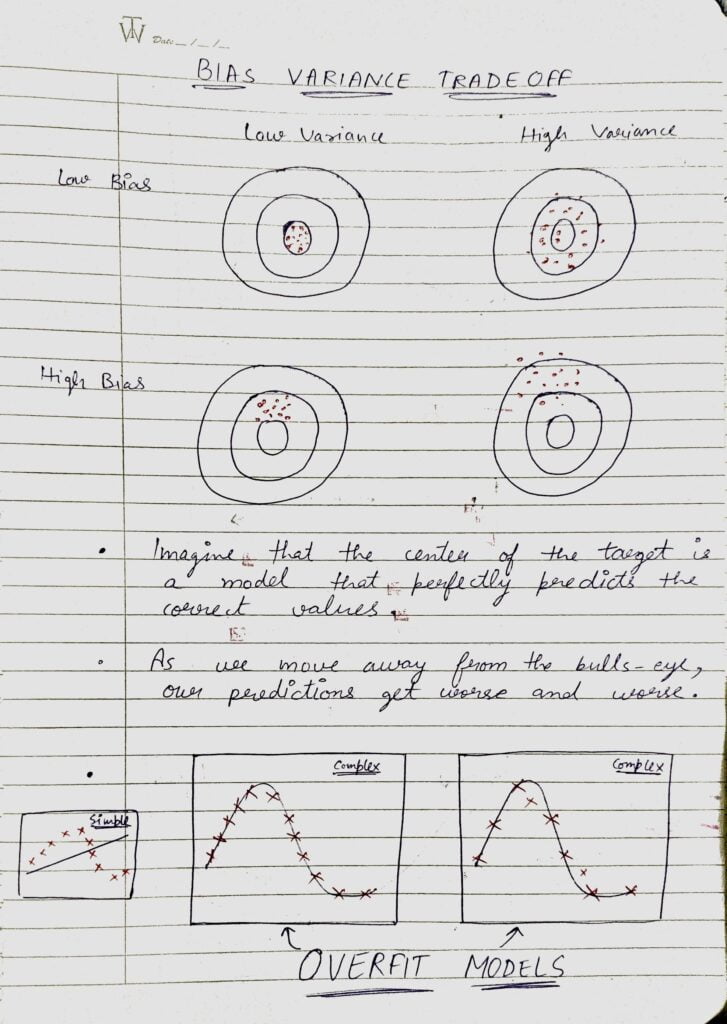
- The bias error is an error from erroneous assumptions in the learning algorithm. High bias can cause an algorithm to miss the relevant relations between features and target outputs (underfitting).
- The variance is an error from sensitivity to small fluctuations in the training set. The high variance may result from an algorithm modeling the random noise in the training data (overfitting).
- Let’s see what the 4 images above depict:
- The first image is having Low Bias and Low Variance, which means that the model is near to the optimal model (low bias) and the points are also not far away from each other (low variance).
- The second image is having Low Bias and High Variance, which means that the model is near to the optimal model (low bias), and the points are spread far away from each other (high variance).
- The third image is having High Bias and Low Variance, which means that the model is far from the optimal model (high bias) and the points are also not far away from each other (low variance).
- The fourth image is having High Bias and High Variance, which means that the model is far from the optimal model (high bias) and the points are spread far away from each other (high variance).
- I have also shown 2 examples of overfitted models in the last. These models are overfitted because these models are not trying to capture the underlying trend of the data but only trying to cover every data point and make bias as low as possible. These models will have very High Variance.
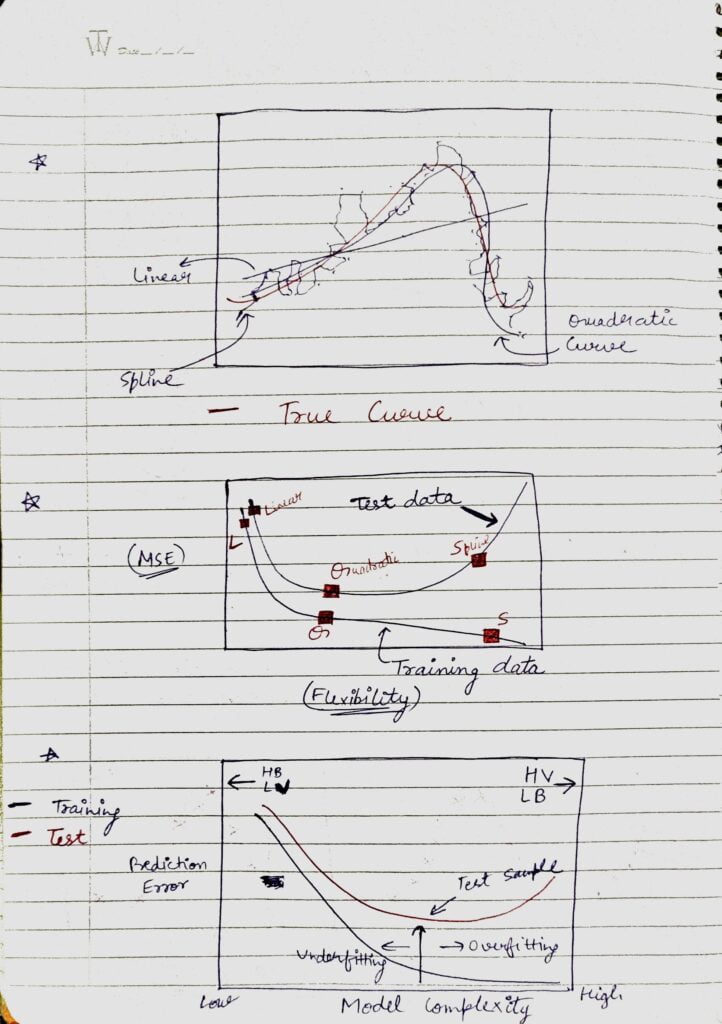
- First Image
- Red Curve is the true curve.
- Linear Curve is the simplest curve. It can also be thought of as Underfitted model. It did not get the trend of the data.
- The quadratic curve is the best curve. It got the underlying trend of the data almost right.
- Spline is the overfitted model. It is just trying to act over smart and cover all the data points.
- Second Image
- We have plotted two curves. One is for training data and one is for testing data.
- For the training curve, Linear is having the highest MSE(Mean Squared Error) because of the fact that it is the underfiitted model, Quadratic is having a lower MSE, and Spline is having the lowest MSE. Spline is having the lowest MSE because it is the overfitted one.
- For the testing curve, Linear and Quadratic are almost the same but for Spline MSE increases because in this case Variance error on the test dataset comes into play due to overfitting.
- Third Image
- It also shows training and testing curves.
- As we go on the left side(lower model complexity), Bias is High and Variance is Less.
- On the other side, if we go on increasing the model complexity(move right side), Bias keeps on decreasing and Variance keeps on Increasing.
So there is always a tradeoff between Bias and Variance. You just need to find a sweet spot in between where the model is performing the best. In the above cases, this spot was the Quadratic model.
Do let me know if there’s any query regarding BIAS VARIANCE TRADEOFF by contacting me on email or LinkedIn.
So this is all for this blog folks, thanks for reading it and I hope you are taking something with you after reading this and till the next time ?…
READ MY PREVIOUS BLOG: LINEAR REGRESSION – LAST-MINUTE NOTES
Check out my other machine learning projects, deep learning projects, computer vision projects, NLP projects, Flask projects at machinelearningprojects.net.





